Today I was changing a csv file into an SQL file. I normally do a lot of my work in Sublime Text, and make copious use of the ctrl+shift+L feature to bring up multiple cursors.
This was my general plan:
write the beginning insert sql statement insert into ... () values
then surround each row of the csv with ( and ) using sublimes multi-cursors. This worked after sublime grinded it's gears for 30 or so seconds (did I mention it's a rather large file I'm doing this to?) but then I realized I had forgotten to put in quotes around my text fields. If my data was nice, I would have simply used multiple cursors and ctrl+arrow keys to drop a quote in, skip over the word, then drop the next quote in and be done with it.
Unfortunately, there's more than one word in some of the text values and the number of words per row was different, so no such luck there.
I popped up vim real fast and figured maybe I could do a nice bit of vim-fu to throw down some quotes. After 10 minutes of googling (you can do vi( and vi) to jump around, but you can't do vi, to jump to a comma in visual mode.) I decided that I didn't know the right search terms to do it and so I opened up libre office figuring it might be able to help me out.
I selected all the cells in my column and went to format cells in the context menu, text type, and made a custom formatter for the cells that just threw quotes around the value. Great! Easy! But wait...
A bunch of values in one of my columns didn't bother to quote themselves. I stared at it for a bit, tried redoing the formatting, clearing it. After a bit I realized that the only difference between the cells that the format was applied to was the squiggly red line underneath each non-formatting cell.
The spell checker prevents a custom formater?
No way, I thought. But I told the spell checker to ignore one of the words, and lo and behold the cell was quoted suddenly. So I shut off the spell checker entirely (it's in options, language, writing aids, and the check while you write option) and had a properly formatted column.
How insane! The Spelling error of a column should most definitely NOT prevent a format from being applied. I wonder if this is a known bug listed somewhere?
Wednesday, October 23, 2013
Friday, September 27, 2013
Time Catcher Usage Demo
http://www.youtube.com/watch?v=H_UhIJah398
So I made a quick demo of timecatcher today out of boredom. Well, actually, I installed Simple Screen Recorder and wanted to try it out on anything at all, so I made the tutorial 3 times and then chose this one as the best out of all of them and uploaded it.
Granted I forgot to show the finish command, but it functions the same way as the pause command does, and to be honest I don't use it that often. A programmers work is never done after all.
So I made a quick demo of timecatcher today out of boredom. Well, actually, I installed Simple Screen Recorder and wanted to try it out on anything at all, so I made the tutorial 3 times and then chose this one as the best out of all of them and uploaded it.
Granted I forgot to show the finish command, but it functions the same way as the pause command does, and to be honest I don't use it that often. A programmers work is never done after all.
Sunday, September 1, 2013
Time Catcher
I've begun work on a new project and so far it's coming along nicely. I've been using some software at work to keep track of my hours, it's called office time. It works fine, simple interface, easy to manage for the most part, and at least 20 features I don't use. Ever. So being the kind of guy I am, I decided that I could probably make a simple to use task tracking utility. Here are some of my motivations.
- I spend about 60-80% of my day in a terminal. So I should be able to access the utility from there
- I need to keep track of a task per day, and then be able to display it meaningfully later on
- I want to be able to add notes to myself about the task as I work on it
- I should only be active on a single task at a time
Keeping track of a single task, well that's simple. Give it a name. I'll have to be able to have it be permanent, and I even have a process running in the background (no) or I make an object of some kind in a file and use that to keep track of things. Now that sounds easy. If it works for git, it will work for me.
If I want to keep track of my tasks per day, I should store these object files into their own folder, named after the current date. The benefit to this is that if I want to generate spreadsheets or information later on, I can do it by date with these folders.
Adding a note, well that's easy too, keep track of it in the file for the current task. Being active on only a single task at a time? Now that seems hard to enforce. Because I'll be able to start a task, then end a task with a command. So I could fire off a bunch of tasks then finish them when I wanted to and the timing data would be complete garbage. Ah! So I'll keep track of the last created task in some type of master file. Easy! When a new task is created, the other task will be 'paused' or for starters I won't let a user switch tasks unless they finish one first.
And this is my first plan. So far it's coming along and I've got the directory to hold this information all good and am writing out the usage documentation, as a guide to me and a guide to anyone else who wants to use it.
Thursday, July 25, 2013
FrankenCode with Rails and Xemark
I've recently created a markup language called xemark. You can find the repository here or the Backus Naur Form grammar here
I've been using it to generate my github pages site which as of the time of this writing is about 75% done.
One of the beautiful things about xemark is that it output's to the console / stdout. Which means you can pipe or direct it's output anywhere you please. Because it prints out it's language to html, this means you can serve up xemark to anything that will pump out html for you.
I just franken coded a rails application to do this.
Now in no way, shape or form, is this good code or practice. But here are the simple steps:
Next, add the following to your config/routes.rb file
And finally, move a file called style.css to the root level of the directory.
And bam. You have style being served.
If I feel like playing more with this, I might make it scan the asset pipeline for the file instead of having it need to be in the root level. For more security, you could do something like this in routes.rb:
Once you do that though, you'll have to change your style get to be just style.css instead of page/style.css though.
I've been using it to generate my github pages site which as of the time of this writing is about 75% done.
One of the beautiful things about xemark is that it output's to the console / stdout. Which means you can pipe or direct it's output anywhere you please. Because it prints out it's language to html, this means you can serve up xemark to anything that will pump out html for you.
I just franken coded a rails application to do this.
Now in no way, shape or form, is this good code or practice. But here are the simple steps:
- Get a copy of xemark. (You can fork the repository, download it, or whathave you, then just compile parser.c with the -o flag set to xemark
- Make yourself a xe file. Heck, use the example.xemark file and rename it example.xe it's up to you.
- Next hop to your console and run the commands
- rails new railsmark
- rails generate controller page showit
- Next we need to put in some code to show call xemark so throw this into your page_controller.rb
class PageController < ApplicationController def showit p = `./xemark < #{params[:page]}.xe` respond_to do |format| format.html {render :text => p} end end end - Finally, move the xemark executable and the example.xe file into the root directory of your rails install.
- run rails s or rails server
- Navigate to localhost:3000/page/showit?page=example
Tada! You've just served up a xe page through rails. Note that this is a toy example, primarily because if you try to include any style to the xe page they won't link well, and not to mention this doesn't make use of the asset pipeline at all in rails, so no styling for you. Still. It was a fun quick and dirty experiment that turned out surprisingly well.
UPDATE:
I made it serve up my style as well. This is assuming that the xe file links to a stylesheet called style.css (by using ~style in the xe file under the @title)
First off. Change the controller code to have a new function
UPDATE:
I made it serve up my style as well. This is assuming that the xe file links to a stylesheet called style.css (by using ~style in the xe file under the @title)
First off. Change the controller code to have a new function
def style
p = `cat ./style.css`
respond_to do |format|
format.html {render :text => p}
end
end
Next, add the following to your config/routes.rb file
get "page/style.css", to: "page#style"
And finally, move a file called style.css to the root level of the directory.
And bam. You have style being served.
If I feel like playing more with this, I might make it scan the asset pipeline for the file instead of having it need to be in the root level. For more security, you could do something like this in routes.rb:
get "example", to: "page#showit" , :page => "example"
Once you do that though, you'll have to change your style get to be just style.css instead of page/style.css though.
Wednesday, July 24, 2013
How to grep a log file in realtime / continuously
When hunting down errors and debugging problems that plague a system. Your log file is your best friend. It lets you know what's going on in your application if you've really put the effort into logging all the idiosyncrasies in your code.
One of my friends once told me: "You have to love your logger" and there's really on true-er statement than that.
Now it's easy to grep a log and look around for what you want. But continuously monitoring a log often poses a problem to people new to the debugging scene. They try out this first:
tail -f logfile | grep "pattern"
And then they wait 4 days for something to show up. Why? Because of line buffering and the output of tail being buffered before being piped to grep. So how do you get around that?
I've seen solutions like this:
tail -f logfile | grep --line-buffered "pattern"
but sometimes, depending on the system, they buffer as well and you have to wait.
To get continuous. real time logging you can employ the following shell script fu:
tail -f logfile | while read line ; do echo "$line"| grep "pattern" ; done
Friday, July 5, 2013
A 'proper' use of GOTO
Ever since Knuth criticized goto people have been spouting that GOTO is the worst language construct to ever use.
It really is logical here and I'll tell you why. Lets look at what I'm doing here in pseudo form:
Now you might be asking me, why didn't you write it with functions and fully modularize your code and encapsulate all the functionality? Simple. This is an exercise from a book. It is mean to be a simple one script that handles a low level functionality of removing comments. It's code is simple and it doesn't benefit from encapsulation (A point that's arguable but only if you're playing devils advocate)
Also, even using functions and all that to encapsulate each portion isn't going to save you the real trouble here unless you place the second while loop into the function. Now why do I have to use goto here? People unfamiliar with scoping rules should be aware that your instinct to throw a continue statement in in order to skip out of the loop will only skip the current block scope you're in. In other words, a continue in the second while will not break you out of the first while like you need to in order for this algorithm to work. A goto statement ignores scope since it's an unconditional branch.
Let the haters commence:
You might ask me, well obviously that scoping thing makes sense, but the program can be rewritten with functions to be clearer. In which case I'd tell you that Occam's razor holds true for small one off programs like this.
But, just to convince you that the use of goto is a "neccesary evil". Take a look here I don't know about you, but I trust the kernel programmers. Considering they wrote your operating system, your drivers, and all the things that make your shiny web applications run smoothly.
I'm fairly sure that 80% of them have never used a GOTO statement in their life, nor understand why sometimes it is the most logical thing to do.
For example here is an example:It really is logical here and I'll tell you why. Lets look at what I'm doing here in pseudo form:
read in a character: read in the next character Does this match a comment statement? Eat the input until the end of the comment No? Then just output it and keep going
Now you might be asking me, why didn't you write it with functions and fully modularize your code and encapsulate all the functionality? Simple. This is an exercise from a book. It is mean to be a simple one script that handles a low level functionality of removing comments. It's code is simple and it doesn't benefit from encapsulation (A point that's arguable but only if you're playing devils advocate)
Also, even using functions and all that to encapsulate each portion isn't going to save you the real trouble here unless you place the second while loop into the function. Now why do I have to use goto here? People unfamiliar with scoping rules should be aware that your instinct to throw a continue statement in in order to skip out of the loop will only skip the current block scope you're in. In other words, a continue in the second while will not break you out of the first while like you need to in order for this algorithm to work. A goto statement ignores scope since it's an unconditional branch.
Let the haters commence:
You might ask me, well obviously that scoping thing makes sense, but the program can be rewritten with functions to be clearer. In which case I'd tell you that Occam's razor holds true for small one off programs like this.
But, just to convince you that the use of goto is a "neccesary evil". Take a look here I don't know about you, but I trust the kernel programmers. Considering they wrote your operating system, your drivers, and all the things that make your shiny web applications run smoothly.
Thursday, July 4, 2013
Book Review: The C Programming Language
The C Programming Language by two really smart guys
The C Programming Language by Brian W. Kernighan, Dennis M. Ritchie is one of the best books I've ever read.
The manner of instruction and the pace it sets is great. There are good explanations on pretty much every subject covered and gotcha's are pointed out whenever there is one. Considering that Ritchie is the creator of the C language and Kernighan is one of the contributors of the original Unix system it's not surprising that the book is so thorough.
The book is small, it's not meant to teach you everything about programming in C, but it's meant to teach you how to use C to express your programming needs. And it does a damn good job of it. The exercises it gives as problems after code listings aren't crap one off programs that you'd write because it's just in the book. But some of them are actually rather useful. For example, The Word Counting (listing 1.5.4) example is a program existing on unix and it's great to see a program that actually exists in the 'real world' of Unix.
I've done a couple of the Exercises out and I've enjoyed it thoroughly so far. I highly recommend purchasing the book or downloading the pdf from the link I provided above.
https://gist.github.com/EJEHardenberg/5931082
The C Programming Language by Brian W. Kernighan, Dennis M. Ritchie is one of the best books I've ever read.
The manner of instruction and the pace it sets is great. There are good explanations on pretty much every subject covered and gotcha's are pointed out whenever there is one. Considering that Ritchie is the creator of the C language and Kernighan is one of the contributors of the original Unix system it's not surprising that the book is so thorough.
The book is small, it's not meant to teach you everything about programming in C, but it's meant to teach you how to use C to express your programming needs. And it does a damn good job of it. The exercises it gives as problems after code listings aren't crap one off programs that you'd write because it's just in the book. But some of them are actually rather useful. For example, The Word Counting (listing 1.5.4) example is a program existing on unix and it's great to see a program that actually exists in the 'real world' of Unix.
I've done a couple of the Exercises out and I've enjoyed it thoroughly so far. I highly recommend purchasing the book or downloading the pdf from the link I provided above.
https://gist.github.com/EJEHardenberg/5931082
Wednesday, June 19, 2013
The knapsack problem and Budgetting.
I created a prototype for my budgeteer program in my last post, and now I can show you the next stage of the application.
Because the other one was implemented in PHP, html, and javascript it suffered from the fact that PHP scripts are meant to die. While I didn't have any trouble with the script timing out, it seems like a better idea to not have to worry about that at all if I don't have to. Therefore, I moved the application to it's new home in a recent project of mine.
In order to figure out if you can afford your budget there are a few thing's to take into account.
Are your fixed expenses greater than your income?
If your rent cost more than your paychecks for the month combined, you have a problem. Hate to tell you, but you simply can't afford wherever you live. If this is the case, then there's no need to attempt the calculation that would figure out what you're able to purchase from your wish list.
Are your expenses covered?
If you're going out to eat every night with friends and spending twenty dollars each time, unless you have a very nice job and a very affordable living situation, it may be a good idea to stop. In fact, if you can't afford your expenses, it makes no sense for you to even try to determine if you can afford anything on your wish list. It makes more sense to keep your wish list, a wishlist.
Finally, what from your wish list can you afford?
If you've managed to get to the point where all your expenses are covered and you can start eyeing your wishlist for possible treasures, then, and only then is your wishlist going to come into the budget calculation.
How do you do it?
So how do you determine if you can afford all these things? Well, it's a pretty well known problem in computer science called the 0-1 knapsack problem (as long as we're not looking into the date's on the budget, as that will elevate it to a job scheduling problem in addition to the knapsack problem -- which is in the works and might be the subject of my next post) that is actually an NP-complete problem. Or at least, part of it is. Luckily for us, there exist approximation algorithms as well as dynamic programming solutions to the problem.
The problem definition is this: I give you a bag that can hold a certain amount of weight, and a list of items that are heavy and have some value. Your job is to get as much value into the bag as possible without going over the weight limit. If you're curious about the solutions to the problem you can check out the Wikipedia page and read all about them. I found that Mikes Coderama was the most useful source as it was fairly easy to use his code as reference and the Wikipedia pseudo code as a guide as I coded my solution.
Now you might ask, how do you translate my budget into a knapsack problem? We simply define the following mappings:
Because the other one was implemented in PHP, html, and javascript it suffered from the fact that PHP scripts are meant to die. While I didn't have any trouble with the script timing out, it seems like a better idea to not have to worry about that at all if I don't have to. Therefore, I moved the application to it's new home in a recent project of mine.
In order to figure out if you can afford your budget there are a few thing's to take into account.
Are your fixed expenses greater than your income?
If your rent cost more than your paychecks for the month combined, you have a problem. Hate to tell you, but you simply can't afford wherever you live. If this is the case, then there's no need to attempt the calculation that would figure out what you're able to purchase from your wish list.
Are your expenses covered?
If you're going out to eat every night with friends and spending twenty dollars each time, unless you have a very nice job and a very affordable living situation, it may be a good idea to stop. In fact, if you can't afford your expenses, it makes no sense for you to even try to determine if you can afford anything on your wish list. It makes more sense to keep your wish list, a wishlist.
Finally, what from your wish list can you afford?
If you've managed to get to the point where all your expenses are covered and you can start eyeing your wishlist for possible treasures, then, and only then is your wishlist going to come into the budget calculation.
How do you do it?
So how do you determine if you can afford all these things? Well, it's a pretty well known problem in computer science called the 0-1 knapsack problem (as long as we're not looking into the date's on the budget, as that will elevate it to a job scheduling problem in addition to the knapsack problem -- which is in the works and might be the subject of my next post) that is actually an NP-complete problem. Or at least, part of it is. Luckily for us, there exist approximation algorithms as well as dynamic programming solutions to the problem.
The problem definition is this: I give you a bag that can hold a certain amount of weight, and a list of items that are heavy and have some value. Your job is to get as much value into the bag as possible without going over the weight limit. If you're curious about the solutions to the problem you can check out the Wikipedia page and read all about them. I found that Mikes Coderama was the most useful source as it was fairly easy to use his code as reference and the Wikipedia pseudo code as a guide as I coded my solution.
Now you might ask, how do you translate my budget into a knapsack problem? We simply define the following mappings:
- Weight Limit becomes our Total Income
- Item Value becomes the Price of any expense
- Item Weight is also the Price of any expense
It's perfectly acceptable to have two properties be the same, if you think about it, it makes perfect sense. If we wanted to get really fancy, then we could allow a user to order the items in their wish lists or expenses by how much they wanted them and use that as a sort of value multiplier, but to be honest, if you're turning towards budgeting software to help out with your finances, you probably shouldn't have too much of an impact on how valuable you find that extra large big mac over paying your rent.
Let's talk high level strategy.
Our application breaks up a user's finances into three categories. Checkbook, Bills, and Wishlist. The Checkbook is the only source of Income as well as a source of expenses. Bills are expenses which we absolutely must pay no matter what. The wishlist is self explanatory.
So first off, we deduct the bills from the income. I thought we were using an algorithm? Don't you worry, we're getting there. But if a user can't afford their bills, then they really shouldn't be spending anything else now should they? Plus, bills tend to be rather high in price, and since our knapsack problem is trying to maximize value of our bag, it's more likely that we'll drop one of our bills in favor of smaller expenses if we have to. And we can't have that since we' need to pay our bills.
This new quantity of income - bills (let's call the resultant lambda), is our weight limit on our first knapsack problem. First? Yes, first, we're going to solve it twice. Once for our expenses, and once for our wishlist. Why you ask? Because if we can't afford our expenses, then we most certainly are not going to look into purchasing anything from our wish list. Agreed?
So lambda becomes the weight limit on our knapsack, and we then feed all of the expenses from our checkbook into the algorithm and wait for it to churn out information. Luckily for us, the algorithm will run in O(nW) time with O(W) space where n is the number of items and W is the maximum weight we'll allow in our bag. This is pretty good for an NP problem, and plus, the number of items in our budget will hopefully be rather small considering it's a monthly budget. (And we're assuming we don't go shopping every other day)
After we've solved the first knapsack problem we can collect the items we included in our bag, and figure out how much money is left over from lambda. Let's call this left over money lambda prime (lambda`) and say it's equal to lambda - (the sum of the values of the items in the previous bag).
Now, we'll construct our second knapsack problem with lambda` as our weight limit and the items being the wishlist items only if we managed to use all the items in our bag. If so, we'll perform the same calculation again and have plenty of information to send back to the user.
It works like a charm.


Sunday, June 9, 2013
Budgeteer Prototype
So I've decided to call my little project Budgeteer (Like a muskateer, yet different!) And I've only been working on it the past few days while I sit on the bus back and forth from work, but it's coming along nicely. I have a rather simple front end with no persistence between page refreshes, and a backend that performs a very simple calculation and sends it's response back. But I do like it. I've also just started playing with css3 media queries in order to detect phones. So I've used a little bit of those to make the application appear nicely on my mobile emulator. I'm using Ripple to do my emulation, and so far I'm enjoying it's injection of tiny hippos (I'm not kidding, check out the javascript log when using the extension.) It's really nice.
Anyway,without further adieu here's the results from this week:
The code itself hasn't made it's way to github yet, and is instead sitting on a private repository on my bitbucket account. Also, you may recognize the color scheme from my previous post about javascript caching, that's because this application is using my little library to cache results so it doesn't need to query for the same thing more than once. Of course, when you submit a request to have your budget analyzed, it's not going to prevent you because you've done the action already, but once I implement the sql side of things (which I probably will soon), I plan on having the budget for a session retrieved from the server with the cache using localstorage so it doesn't have to be done more than once. Of course I do need to checkout if local storage is preserved between page refreshes or not.
Anyway,without further adieu here's the results from this week:
 |
| What it looks like in a browser |
 |
| What it looks like on a phone (emulated by Ripple) |
The code itself hasn't made it's way to github yet, and is instead sitting on a private repository on my bitbucket account. Also, you may recognize the color scheme from my previous post about javascript caching, that's because this application is using my little library to cache results so it doesn't need to query for the same thing more than once. Of course, when you submit a request to have your budget analyzed, it's not going to prevent you because you've done the action already, but once I implement the sql side of things (which I probably will soon), I plan on having the budget for a session retrieved from the server with the cache using localstorage so it doesn't have to be done more than once. Of course I do need to checkout if local storage is preserved between page refreshes or not.
There's still a lot of variables to be done before this small application is done and doing something really cool, but for not it's just a neat little application with room for improvement. I plan on adding some more budget buddy-esk features in (dates and whatnot) and then plan on having the tool use that type of information to advise you
Thursday, June 6, 2013
Caching with javascript and HTML5 local storage
I am creating my own Javascript library to cache the results of a request to certain URLs. What happens at the core of this, is thus:
If we haven not yet cached the url we submit our AJAX request to the server, if we have cached the result, we return that instead. Sounds like a pretty simple concept to me. And it turns out, with a little bit of work it's not too hard to implement.
http://pastebin.com/drrqi8Pw
Instead of crudely pasting the code into this post, I've included it in the paste above. while this code will not run if you just plug it into a file (local dependencies on the library I'm making), you can get the general idea of how it works.
A use case can go something like this:
The user calls some function out of the library (such as getBudget) which, after making sure parameters are correctly, sends the url and a requestHandler to the apiRequest function. The url is parsed into just the important parameters and checked against the cache. If it's in the cache that object will be passed as an argument to the users requestHandler, if not, then we'll make the ajax request. Assuming we've made the ajax request, during the respond we'll pass the response JSON to the user's function first, and then we'll perform whatever operations we need in order to store it locally and mark the url we used to get it as cache-able.
You'll notice that I've included the apiSendDate in the paste as well, this is because we need to map CRUD operations (minus the R) to URLs that retrieve that data. This is abstracted away into the apiURLMap object, which (if the finance tool becomes complicated --which it will) will eventually become a function in order to map a single URL to multiple url's that would correspond to stale information.
To prove to you that this works (since I provided non-functioning code above) here's a couple screenshots of my mock prototype --please keep in mind front end is not important to me until the functionality is there--
 |
| Network traffic for first submission |
S
 |
| Submitting a request by clicking the Get Items link |
 |
| Submitting a second request, uses the cache |
 |
| Second shot of the network requests, only the first one is there, so we've saved ourselves the trip to the server |
Note: Just to let everyone know, localStorage can only store strings by default unless you override the eprototypes, that's why we stringify the data before placing it into the local storage
Sunday, June 2, 2013
Finance applications
For whatever reason, I find myself constantly thinking of making software to assist with budgeting and managing your personal finances. For some reason I feel a strong pull in that direction. Now that I've got a bit of Data Mining under my belt after studying with Xindong Wu I think it's time I applied it. Association analysis is a beautiful thing.
Also, when I first created budget buddy, it was more of an online checkbook. I've started a new project that I plan on making a far more in depth tool. I'm envisioning a php front end with the heavy lifting done by C if necessary Why C and not something like ruby or java? Well, it might just be my general desire to create from scratch, but I really love the feel of working with C or C++. Hell, I'd love to play with Assembly if possible with this project, but that probably won't happen. Maybe some OCaml though or ML. I could use the Google App Engine and Python to create an application, but for whatever reason I've been digging on Javascript recently, and I don't mean jQuery, I mean pure Javascript, in fact I've made a couple tutorials to keep myself busy and as an exercise in explanations.
As I create the application I plan on posting here a bit with details, and as always the code will probably make it's way up onto github. More to come!
Also, when I first created budget buddy, it was more of an online checkbook. I've started a new project that I plan on making a far more in depth tool. I'm envisioning a php front end with the heavy lifting done by C if necessary Why C and not something like ruby or java? Well, it might just be my general desire to create from scratch, but I really love the feel of working with C or C++. Hell, I'd love to play with Assembly if possible with this project, but that probably won't happen. Maybe some OCaml though or ML. I could use the Google App Engine and Python to create an application, but for whatever reason I've been digging on Javascript recently, and I don't mean jQuery, I mean pure Javascript, in fact I've made a couple tutorials to keep myself busy and as an exercise in explanations.
As I create the application I plan on posting here a bit with details, and as always the code will probably make it's way up onto github. More to come!
Wednesday, May 29, 2013
Grails. Creating an Inventory Tracking System
So I recently moved, during the move I thought about writing down a list of all the things I had like I had done in prior years, then I realized I could do something a bit better. Why not make a tracking system on my computer? My laptop travels everywhere with me and having my own system running on a local server would work just fine.
For an upcoming job, I need to learn Grails. Groovy on Rails is one of the newer frameworks to come out, so it was a little troublesome to find a good guide to starting. I found the user guide but was instantly turned off by the HUGE amount of knowledge suddenly thrown at me. Being a normal human being, I instantly turned to finding some simple tutorials to help me out.
After watching the 3 screen casts and troubleshooting an error of my own that wasn't covered (modifying the bootstrap file to add a correct instance of a Task), I decided that I had enough information to try to throw together a tutorial of my own (blind leading the blind!).
Without further a due, here we go:
First off I navigated to where I wanted the project to be and ran the grails create-app Inventory command to create my project

A Quick Side Note: I run my grails command with the argument grails -Dserver.port=9090 because I run an apache2 webserver as well which sits on my 8080 port. Since I don't care to stop my apache2 server whenever I'm working on something slightly different (I do switch between servers when I switch between certain projects), it's just easier to change the port grails runs on with a quick command. When I first installed grails a few weeks ago, I hunted for the default port setting but had no luck finding it.
The funny looking error screen occurs because we have no index.gsp page for the controller we've just created. Yes that is not a typo, grails looks for index.gsp first, then defaults back to looking for index.jsp. We want to make a groovy server page next, not a java server page. But before we do that, let's go ahead and make a second domain class called Type (which surprisingly is not a reserved word in Groovy) that we'll use to be able to sort through the items we're keeping track of.
Now run the following commands in the grails console:
create-domain-class Type
create-controller Type
Simple so far right? The nice thing about using a framework is that SO much get's done for you with a few simple lines. So at this stage we have our objects and their relationships, and now we just need to display them and provide an interface to the user.
And this is what it all looks like right now:

Next, we want to display each items type next to it, so we'll add in a toString method to the type domain class, and modify the index page to output the type of the item as well.
Next we probably want to give the User the ability to add and edit their own stuff and types. So we can add a couple of links in, I've also modified the list to use table tags instead of list tags since this type of data is better represented in tabular form.
And there you have it, a simple inventory tracking system made in grails within a few minutes.
For an upcoming job, I need to learn Grails. Groovy on Rails is one of the newer frameworks to come out, so it was a little troublesome to find a good guide to starting. I found the user guide but was instantly turned off by the HUGE amount of knowledge suddenly thrown at me. Being a normal human being, I instantly turned to finding some simple tutorials to help me out.
After watching the 3 screen casts and troubleshooting an error of my own that wasn't covered (modifying the bootstrap file to add a correct instance of a Task), I decided that I had enough information to try to throw together a tutorial of my own (blind leading the blind!).
Without further a due, here we go:
First off I navigated to where I wanted the project to be and ran the grails create-app Inventory command to create my project

Next, I create a Domain class so that I'll have the ability to connect classes together through relationships in the database, as well as it's controller so that I'll have something "nice" to look at when I try to navigate to the controller in my url. Below are screenshots of the sequence of commands, as well as the "nice" thing to look at. You can see that I restarted my app after making the controller. I did this without CTRL-C'ing the application by creating an empty file called .kill-run-app in the top level of my grails project. This is a shortcut to stopping a server that I found here.
The commands I executed to create the domain class, it's controller and to run the app are here:
create-domain-class Item
run-app
create-controller Item
run-app (after killing it with the .kill-run-app trick)
 |
| What the initial controller looks like (error explained in a moment) |
 |
| The commands to create domain class and controller |
Now run the following commands in the grails console:
create-domain-class Type
create-controller Type
 |
| Creating another domain class and controller |
 |
| The running app can see it's controllers. Navigating to these will give you the error page from before |
Tada! Now let's actually start coding. What we want to do is add some property fields to the two domain class's so they'll actually be useful, and then we'll want to assure ourselves that everything is working nicely. Blogger doesn't have a good source code format so I'll just be throwing in screenshots of my text editor.
The files we'll modify are:
grails-app/domain/inventory/Item.groovy
grails-app/domain/inventory/Type.groovy
grails-app/controllers/inventory/Item.groovy
grails-app/controllers/inventory/Type.groovy
In the two domain class files, we'll add in the properties and define some constraints on the system. For each Item we'll need a name, a description of what the item is, where the item is and how many of the item we have. The constraints on Item's will be that their name and location can't be blank, that there must be at least 0 of them, and the name of the Item is unique. Type's are pretty simple, they need a unique non-blank name and that's it. Between the two we define their relationship as Many-To-Many using the static hasMany and static belongsTo properties. It's fairly intuitive to see how groovy expresses that we have many types of a class called Type in that one hasMany statement. In order for the relationship to function, one side of the relation has to belong to another, in this case, the Type belongs to the Item, which means that we add the static belongsTo=Item line into the Type domain class.
Within the controllers we remove the automatically defined index function, and simply add the line:
static scaffold = Type inside the type controller, and static scaffold = Item inside the Item Controller. This sets us up with a CRUD(Create, Read, Update, Delete) view.
 |
| The source code so far |
 |
| A simple CRUD interface by specifying scaffold to the type, or to true |
Simple so far right? The nice thing about using a framework is that SO much get's done for you with a few simple lines. So at this stage we have our objects and their relationships, and now we just need to display them and provide an interface to the user.
To do this, we're going to modify the default index.gsp file since it's got some nice styling that we can use right off the bat. First off we'll want to remove the Grails image form the top right. To do that we'll edit the file grails-app/views/layouts/main.gsp
 |
| Changing the layout file |
I've hacked it a bit, simply removing the src of the image and forcing the image to be invisible with some (evil) inline css. This is the fastest way to keep the nice green boarder grails provides us with, and do away with their image all at once. If you simply remove the img tag, then the green bar at the top will collapse down to 0 height and that's no good.
Next we edit grails-app/views/index.gsp to be pretty much blank so that we can have at it. I've taken out most of the html content, changed the title tag in the head, and left a snippet of code we'll be modifying to display out items.
 |
| Modifying the index page |
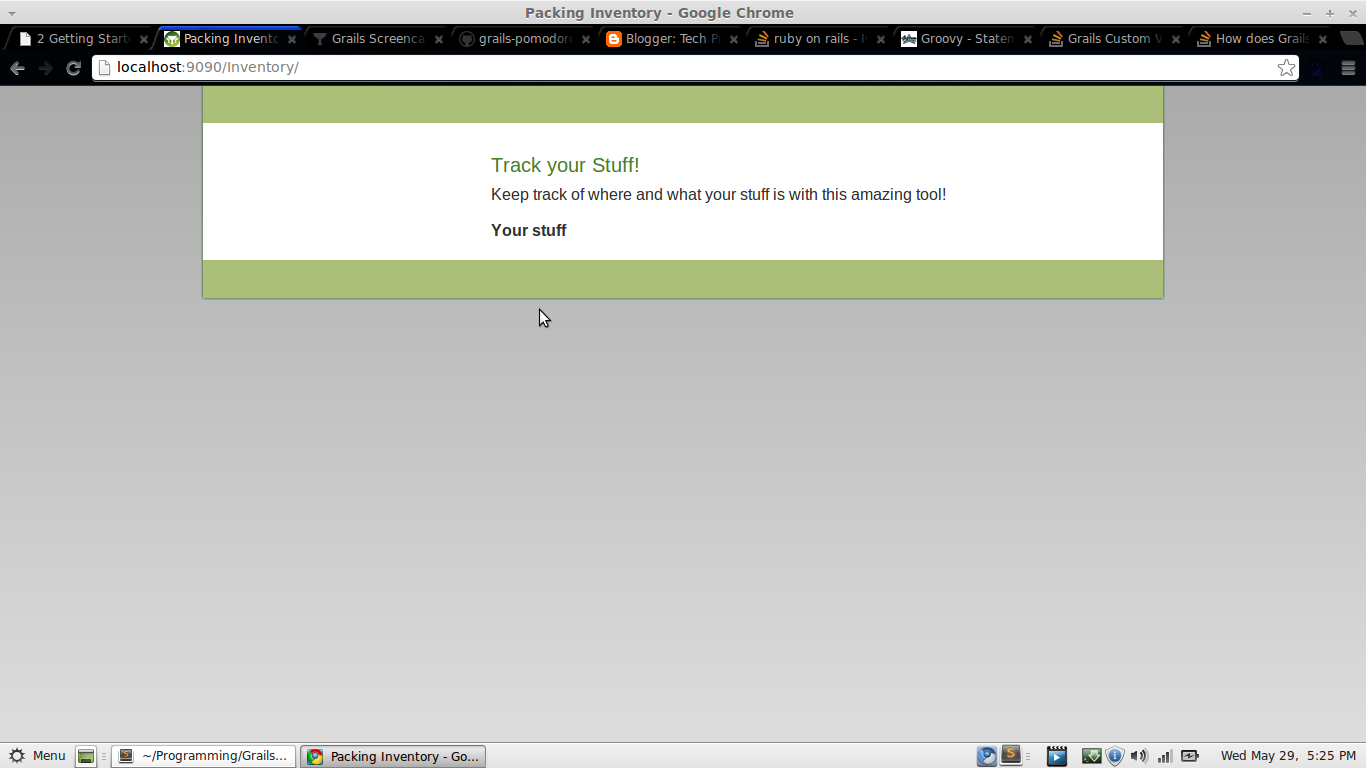
Unfornately, how to throw interesting data onto your index page is not immediately apparent in Grails since it's using what looks like static information to me. SO, with some help from stackoverflow, we can edit the grails-app/conf/UrlMappings.groovy file to send the index page along to a controller. So we need to make that controller! Running create-controller Index will do the trick just fine. Then we can copy the default index.gsp file to the grails-app/views/index/index.gsp file and then our new Url Mappings will work just fine!
 |
| Create the new controller. Whenever you want a new page, you pretty much make a new controller |
Now we need to pull information from both the Types and the Item's controllers. To do that we'll hop into the IndexController located in grails-app/controllers/inventory/ and add some values for us to send along. See the screenshot of the controllers code on the right, and the changes to the index.gsp file to make things appear.
 |
| Houston, we have liftoff |
 |
| And the code doing the work, we haven't used the types yet, but we will! |
 |
| Add the toString function to type and modify the index file to output it |
 |
| The result of the toString and output |
 |
| Add links to allow users to edit |
 |
| The User interface now |
Tuesday, May 21, 2013
Functors, Applicatives, and Monads
http://adit.io/posts/2013-04-17-functors,_applicatives,_and_monads_in_pictures.html
Today I found this really great page through the Computer Science Twitter. IT does a really good job of explaining functors, applicatives, and monads in Haskell. It's a good way to brush up on your functional programming! It's worth a read, and it's done primarily through pictures so if you're a visual learner like I am, you'll have a blast.
Today I found this really great page through the Computer Science Twitter. IT does a really good job of explaining functors, applicatives, and monads in Haskell. It's a good way to brush up on your functional programming! It's worth a read, and it's done primarily through pictures so if you're a visual learner like I am, you'll have a blast.
Tuesday, April 16, 2013
How to make a patch using git and apply it! C binary file.
As I was walking home from work today I got to thinking about patch files for some reason. Don't ask me, I just did. So I'm walking along, and thinking about how git has patch files as pretty simple things of add this in, take this out. Do that a bunch of times and poof. And I know what it looks like for source code. But then I also entertained the thought about executable files.
So without further a due:
First let's make a directory and hop into it.










So without further a due:
First let's make a directory and hop into it.

Next, let's make our C file

Now compile the program...

Now comes the fun part. Make a new repository and commit it

Now let's make a change to the program

Now recompile the program and check out the status of our repository

We can see that we've modified everything (because we have) and that git is keeping track of our binary for us. So now how do we make a patch? Well, the easiest way to do it is to put these changes on another branch. This will let use some really easy to follow commands. So let's do that.

Next, I'll clear my console with clear and then create the patch. Because I'm alternating between a fullscreen guake terminal, and this blog post I get some weird spacing and the actual patch command to make a bazboz patch file from our current branch is about halfway down the screen.

Now, something you might notice is that since I've been using git add . I've not only added the binary file to the patch, but also the changes to the source code. If I was maintaining some type of non-open source project, or it was a configuration file that wasn't ignored for whatever reason, I would have only added the binary file to the patch. Not a big deal, but just something to take note of. To actually apply the patch file we've made, lets go ahead and switch to master

you might notice I'm already on master, that's just because I switched over in a separate terminal window and was testing the commands I was doing first, that way this little tutorial stays clean. Once I've switched to the master branch I check to see if the patch is going to fail. Since no warnings or errors pop up from the check option from apply. We can go ahead now.

We could have applied the patch with git apply but if we use git am we sign off on the patch so that everyone who helps us maintain our code can point their fingers at us when something goes horribly wrong and our code is at fault.
And that's all there is to it! Note that this is a pretty minimal example, and to be honest a patch really isn't necessary at all. If I were just grabbing a commit from another branch I would use git cherry-pick and select the hash of the commit I wanted to grab. But, if you were working on a project like, Drupal or some other large open source and you contributed to core modules and such, they'd probably want to take a patch to make it easy on them to integrate your changes.
I didn't go into too much detail about anything I was doing I don't think, and if you want a more detailed explanation with a bit more time spent, I recommend This tutorial by Ariejan de Vroom
If you were emailed this patch file, you'd cd to your repository, checkout to your master branch (or whatever branch you want to apply the patch to) and then run the git am commands after dropping the patch file into the directory. Easy!
Wednesday, April 3, 2013
Easy Problem of Satisfiability
Problem:
Given an expression consisting of AND,OR, and NOT gates, determine whether or not the output of the circuit can be made high. That is, the circuit has I inputs, N gates, and 1 final output.
Solution:
I have one. This problem was described to me as the natural NP problem. Yet, it is extremely easy to solve in linear time at worst. Which confuses me. An NP problem should take sub-exponential or exponential or worse time to complete. Yet the algorithm I have come up with (I swear it's not in the margin of my notebook, actually takes up just a page) finds not only if the circuit is satisfiable but also implicitly gives back the neccesary input to cause the circuit to output low. Another caveat of my algorithm is that it can be used to find a way to cause a circuit to return low as well. It is very general, and the algorithm itself takes up only 150 lines of code or so. It's a beautiful recursive descent.
I'm meeting with my professor in a half hour to go over it with him. And after this, I will know if I have found a solution to the NP problem of Circuit satisfiability or if I missed the problem definition in some way and merely solved a problem similar, yet easier.
If all goes well, I'll post my algorithm later on today.
Given an expression consisting of AND,OR, and NOT gates, determine whether or not the output of the circuit can be made high. That is, the circuit has I inputs, N gates, and 1 final output.
Solution:
I have one. This problem was described to me as the natural NP problem. Yet, it is extremely easy to solve in linear time at worst. Which confuses me. An NP problem should take sub-exponential or exponential or worse time to complete. Yet the algorithm I have come up with (I swear it's not in the margin of my notebook, actually takes up just a page) finds not only if the circuit is satisfiable but also implicitly gives back the neccesary input to cause the circuit to output low. Another caveat of my algorithm is that it can be used to find a way to cause a circuit to return low as well. It is very general, and the algorithm itself takes up only 150 lines of code or so. It's a beautiful recursive descent.
I'm meeting with my professor in a half hour to go over it with him. And after this, I will know if I have found a solution to the NP problem of Circuit satisfiability or if I missed the problem definition in some way and merely solved a problem similar, yet easier.
If all goes well, I'll post my algorithm later on today.
Saturday, February 9, 2013
The Smart Desk
https://github.com/EJEHardenberg/SmartDesk
I've started a new project! Working on it with one of my friends who graduated last year, he's working on the Networking component and I'm working on the graphical component. It's a very promising idea in my head, and will get a lot of experience with system programming. I'm looking forward to it.
:)
I've started a new project! Working on it with one of my friends who graduated last year, he's working on the Networking component and I'm working on the graphical component. It's a very promising idea in my head, and will get a lot of experience with system programming. I'm looking forward to it.
:)
Sunday, January 20, 2013
EEG and Cairo
Using the outline in this video:
http://www.youtube.com/watch?v=ZmxmeRry2uY
And an arduino board from a friend, I plan to create a small program that will display the output of the eeg onto the screen.
As my recent kick is with C, I think I'll do that. My current plan is to create a couple different programs, one that handle the graphics and another that will handle getting information from the eeg. That way I can develop one while I assemble the EEG. I think I'll be using Cairo Graphics or OpenGL not sure which yet, I've selected Cairo because it seems like its easy to work with from the examples I've seen. And then I'll have a memory mapped file, or named pipe between the two programs so that they can share data quickly and efficiently.
http://www.linuxquestions.org/questions/programming-9/mmap-tutorial-c-c-511265/
Hopefully this all works out nicely, and if I don't manage to assemble an EEG, then at least I've worked with graphics and memory mapped files. Which I think could become a key staple to learning some parrallel processing techniques.
http://www.youtube.com/watch?v=ZmxmeRry2uY
And an arduino board from a friend, I plan to create a small program that will display the output of the eeg onto the screen.
As my recent kick is with C, I think I'll do that. My current plan is to create a couple different programs, one that handle the graphics and another that will handle getting information from the eeg. That way I can develop one while I assemble the EEG. I think I'll be using Cairo Graphics or OpenGL not sure which yet, I've selected Cairo because it seems like its easy to work with from the examples I've seen. And then I'll have a memory mapped file, or named pipe between the two programs so that they can share data quickly and efficiently.
http://www.linuxquestions.org/questions/programming-9/mmap-tutorial-c-c-511265/
Hopefully this all works out nicely, and if I don't manage to assemble an EEG, then at least I've worked with graphics and memory mapped files. Which I think could become a key staple to learning some parrallel processing techniques.
Thursday, January 17, 2013
Brain Fuck Interpreter. I made one
https://github.com/EJEHardenberg/BF_Interpret
So After a couple of days I've scrapped together my small amount of knowledge of C and created a BrainFuck interpreter.
It was pretty simple since all you're really doing is manipulating a Turing Machine. But creating the interactive bits was fun and a good thought exercise.
There are a few ways to run it once you've compiled it.
Just run it with no arguments:
Gets you the interpreter. Where you can type in all the BF commands you'd like, or comments as long as they don't include 'q' becuase 'q' is the quit key.
arguments of -f filename will read in a file and that file will be fed to the BF translator and outputted according to whatever program you decide.
arguments of anything else: will be taken as BF code and interpreted.
It's a pretty basic program, but it was a good exercise, and I'm going to refactor the code a bit. A friend of mine pointed out that the headers should be just declarations and not full blown source code.
So After a couple of days I've scrapped together my small amount of knowledge of C and created a BrainFuck interpreter.
It was pretty simple since all you're really doing is manipulating a Turing Machine. But creating the interactive bits was fun and a good thought exercise.
There are a few ways to run it once you've compiled it.
Just run it with no arguments:
Gets you the interpreter. Where you can type in all the BF commands you'd like, or comments as long as they don't include 'q' becuase 'q' is the quit key.
arguments of -f filename will read in a file and that file will be fed to the BF translator and outputted according to whatever program you decide.
arguments of anything else: will be taken as BF code and interpreted.
It's a pretty basic program, but it was a good exercise, and I'm going to refactor the code a bit. A friend of mine pointed out that the headers should be just declarations and not full blown source code.
Subscribe to:
Posts (Atom)